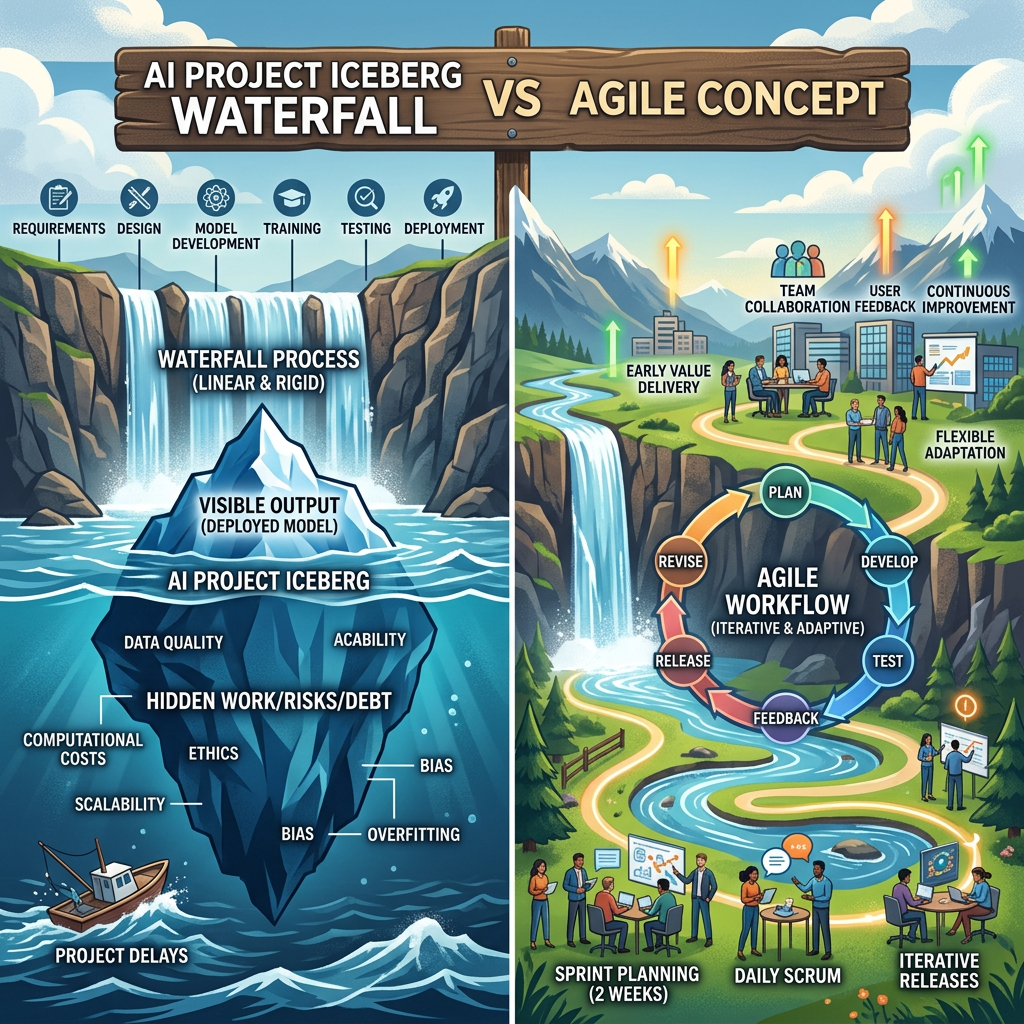
Dalla cascata alla marea: processi che funzionano
L’altro giorno, mentre lavoravo su un modello che si ostinava a degradare in produzione al primo refolo di drift, mi sono chiesto perché continuiamo a usare modelli di progetto pensati per ponti e non per sistemi socio-tecnici. In questo articolo rifletto, in prima persona, sulle ragioni per cui il modello Waterfall fallisce nei progetti di intelligenza artificiale e su quali metodologie funzionano davvero: CRISP-DM, TDSP, MLOps, GenAI Lifecycle e Agile AI. L’approccio combina evidenze da letteratura recente, dati di survey industriali e trent’anni di cicatrici professionali. La conclusione è pratica: occorre progettare per l’incertezza, lavorare per thin vertical slices e mettere MLOps, valutazione e governance nel contratto fin dal giorno 0. La vera sfida non è tecnica, ma umana.
Introduzione
L’altro giorno, mentre lavoravo su un “semplice” retraining, ho scoperto che il feature store aveva perso coerenza su due join “banali”. L’alert? Silenzio. Il modello? In stallo. Ho sorriso amaramente: trent’anni fa mi preoccupavo dei backup su nastro, oggi dei data contract tra team che non si parlano abbastanza.
Nella mia esperienza, l’AI mette in crisi i riflessi condizionati di chi è cresciuto con Waterfall: prima i requisiti, poi il design, poi l’implementazione, test, consegna. Schema elegante, rassicurante. Ma l’esperienza sul campo mi ha insegnato che i sistemi di machine learning vivono in ambienti complessi, dove i requisiti si scoprono mentre impari dai dati, e dove “finito” non è una data ma una curva ROC che balla nel tempo.
Il punto di questo articolo è spiegare perché Waterfall fallisce nei progetti AI e quali metodologie hanno retto meglio sotto stress: CRISP-DM, TDSP, MLOps, GenAI Lifecycle e Agile AI. Condivido pratiche, metriche e un frammento di pseudocodice di sprint che applico con i miei team. Spoiler: il processo non salva il progetto, ma un buon processo riduce l’attrito per far emergere i rischi presto.
Background: La Storia che Abbiamo Dimenticato di Imparare
Quando ho iniziato, il riferimento era Waterfall: fasi sequenziali, gate chiari, responsabilità nette. Una meraviglia per sistemi deterministici, meno per sistemi apprendenti.
La letteratura sulla failure dei progetti IT non è tenera: i dati suggeriscono tassi di insuccesso persistenti nel tempo, con una domanda fondamentale ancora aperta — perché, nonostante strumenti più avanzati e framework maturi, i progetti IT continuino a fallire a tassi sostanzialmente invariati? (Arcidiacono, 2026, PM World Library). [pmworldlibrary.net]
Prima dell’hype AI, il data mining aveva adottato CRISP-DM: una metodologia iterativa con fasi di Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation e Deployment. CRISP-DM riconosce che la conoscenza si crea iterando tra dati e problemi, non compilando requisiti e basta. Nella mia esperienza, CRISP-DM è stato il primo scarto culturale rispetto a Waterfall: integra la scoperta nel ciclo, invece di spostarla in un’analisi infinita.
Con l’esplosione dell’AI in produzione, il problema si è allargato: non basta costruire il modello, bisogna operarlo. MLOps è emerso come ricetta per standardizzare le soluzioni ML negli scenari di deployment: è un insieme di pratiche che mira ad automatizzare la delivery dei modelli ML in produzione, adottando i principi DevOps — in particolare continuous integration e continuous delivery — per i sistemi ML. (Bayram & Ahmed, 2024, Karlstad University). [arxiv.org]
In parallelo, l’integrazione della GenAI nello sviluppo Agile sta rimodellando il modo in cui i team automatizzano compiti, ottimizzano processi e migliorano l’esperienza utente. (Springer, 2025). Il risultato? Un mosaico di processi che cercano di rispondere a una domanda semplice: come ridurre l’incertezza prima che riduca noi?[link.springer.com]
Analisi Scientifica
Perché il Waterfall Fallisce nell’AI
Affermazione citabile:“I progetti AI non falliscono nell’implementazione, falliscono nell’apprendere abbastanza in fretta.”
L’altro giorno, mentre lavoravo su un dataset “congelato”, ho scoperto che il concetto di “congelato” in produzione valeva 48 ore. Questo chiarisce il primo punto strutturale: Waterfall presume requisiti stabili e ambienti controllati. Nei progetti AI, i requisiti sono ipotesi sulla relazione tra dati, modelli e valore — e l’ambiente evolve.
La cornice Cynefin di Dave Snowden classifica questi contesti come complessi: causa ed effetto sono conoscibili solo a posteriori, attraverso safe-to-fail experiments, non fasi rigide. È l’ambiente naturale dell’AI.
L’integrazione dell’AI nel project management promette di liberare i project manager dalla gestione opprimente dei dati, consentendo di ridurre la complessità e concentrarsi maggiormente sul processo decisionale strategico. (ScienceDirect, 2025) — ma questo vale solo se il processo permette di apprendere. Waterfall lo impedisce strutturalmente. [sciencedirect.com]
CRISP-DM e TDSP: Iterazione come Prima Difesa
CRISP-DM ha avuto successo perché normalizza la scoperta. Nella mia esperienza, applicarlo letteralmente oggi non basta, ma il principio resta: tornare indietro velocemente quando un’ipotesi non regge ai dati.
Il Team Data Science Process (TDSP) di Microsoft ha preso quel cuore e lo ha esteso: repository strutturati, artefatti condivisi, checklist di qualità dei dati, focus su cicli sperimentali e su MLOps light. La forza di TDSP è la concretezza: template, metriche, definizioni di done per gli esperimenti — non solo per le feature.
Ma l’esperienza sul campo mi ha insegnato che nessun processo funziona se non include criteri di stopping e metriche di incertezza. Incorporare misure come expected calibration error, population stability index, o — per GenAI — rubriche di valutazione human-in-the-loop è cruciale già nella fase di modeling, non alla fine.
MLOps: Robustezza, Affidabilità, Osservabilità
MLOps serve come compagno vitale durante tutto il ciclo di vita dei prodotti AI, garantendo monitoraggio continuo e delivery dei sistemi ML.La ricerca sulle sfide di adozione di MLOps indica che alcune problematiche, come la complessità dei dati e dei modelli, sono peculiari di MLOps, mentre altre sono condivise con DevOps. (ScienceDirect, 2024, Journal of Innovation & Knowledge). Le tre frizioni ricorrenti che rilevo sul campo: [arxiv.org][sciencedirect.com]
- Barriere organizzative e culturali — responsabilità frammentate tra team di data science, IT e business
- Integrazione toolchain — patchwork di strumenti non orchestrati
- Competenze ibride scarse — ML + SRE + Governance nello stesso profilo
Nella mia esperienza, la soluzione pratica è trattare MLOps come parte del prodotto, non come “fase dopo”. In concreto:
- Pipeline riproducibili fin dal primo esperimento utile
- Data contract espliciti con i domini a monte
- Metriche leading (drift, tasso di rifiuto, confidenza) oltre alle lagging (AUC, NDCG, BLEU)
- Ambienti shadow per testare in produzione senza impattare l’utente
Affermazione citabile:“Un modello senza telemetria è un’opinione con un endpoint.”
GenAI Lifecycle: Valutare, Allineare, Proteggere
Con GenAI, il problema non è solo predire, è generare. L’integrazione della GenAI nello sviluppo Agile sta rimodellando il modo in cui i team automatizzano compiti e ottimizzano processi. Questo richiede un lifecycle dedicato che include: [link.springer.com]
- Prompt engineering come artefatto versionato
- Set di valutazione multimodali (non solo benchmark)
- Metriche di allineamento: coerenza, fattualità, danno
- Circuiti RLHF o preference data
- Guardrail e filtri di sicurezza integrati nella pipeline
Nella mia esperienza, adottare un GenAI Lifecycle significa mettere la valutazione al centro. Valutazioni offline (golden sets, rubriche) e online (A/B, interleaving) devono convivere — altrimenti si ottimizza per metriche surrogate che non reggono alla realtà del cliente.
Agile AI e Thin Vertical Slices
La combinazione di Agile con AI e GenAI produce miglioramenti in aree chiave: user story e backlog item raffinati dall’AI, identificazione e previsione di colli di bottiglia nei workflow, e grandi dataset che forniscono insight azionabili per il processo decisionale. [forbes.com]
Agile AI non è fare “Scrum con un modello” — è strutturare il lavoro in thin vertical slices: incrementi end-to-end che attraversano dato, modello, deployment e misure, anche se “piccoli e brutti”. Una slice valida nella mia pratica include:
- Un canale dati minimo affidabile
- Un baseline modello/prompt riproducibile
- Un deploy in shadow (canary 5%)
- Una metrica di outcome osservabile
- Una decisione esplicita: continuare, pivotare, fermare
Pseudocodice — uno sprint Agile AI da 10 giorni:
sprint_AI(10_giorni): day1: define_problem() define_primary_metric(owner="PM") list_three_hypotheses() day2-3: data_audit() baseline_non_ml() # heuristic o rule-based set_data_contracts() day4-5: build_baseline_model_or_prompt() version_artifacts(repo="mlops") day6: offline_eval(golden_set, metrics=["AUC","calibration","cost"]) decide(go/no-go/adjust) day7: infra_tasks(pipeline_min, feature_store_binding, CI) day8: deploy_shadow(canary=5%) enable_telemetry(drift, latency, harm_signals) day9: error_analysis() ab_test_if_safe() day10: review(learned_risks, value_metrics) plan_next_thin_slice()
Ma l’esperienza sul campo mi ha insegnato che lo sprint “perfetto” non esiste: il valore sta nelle decisioni esplicite su cosa fermare, non solo su cosa continuare.
Tabella: Cause di Fallimento e Mitigazioni
| Causa di Fallimento | Descrizione | Mitigazione Operativa | Fonte |
|---|---|---|---|
| Requisiti instabili | Ipotesi errate su dati e obiettivi | Discovery time-boxed, thin slices | Arcidiacono (2026) |
| Debito sui dati | Qualità, diritti e drift non gestiti | Data contracts, QA continuo | Bayram & Ahmed (2024) |
| MLOps tardiva | Toolchain e ruoli frammentati | MLOps by design, SRE ML | ScienceDirect (2024) |
| Valutazione GenAI debole | Metriche surrogate non correlate al valore | Golden sets, rubriche HIL, A/B | Springer (2025) |
| Governance assente | Compliance, sicurezza, etica non integrate | Checkpoint rischio nel ciclo | ScienceDirect (2025) |
| Silos ML/IT | Handoff lenti e responsabilità opache | Team cross-funzionali | SpryFox (2025) |
❓ FAQ: Tre Domande che Ricevo Sempre
Perché non possiamo “definire tutto all’inizio” e poi costruire? Perché nell’AI i requisiti sono ipotesi su dati e comportamenti futuri. I dati suggeriscono che conoscere la verità costa meno se lo fai presto e spesso, non alla fine del progetto quando correggere è massimamente costoso.
Possiamo fare Waterfall per la piattaforma e Agile per i modelli? Nella mia esperienza, sì — ma con cautela. La piattaforma vive degli stessi feedback loop del modello. Senza telemetria e slices end-to-end, rischiate due Waterfall separati che si rincorrono senza mai convergere.
Come convincere il business che “sperimentare” non è “perdere tempo”? Misurate l’outcome di ogni slice e collegatela ai rischi ritirati. “Riduzione dell’incertezza” è un deliverable — se lo rendete visibile al cliente, smette di sembrare overhead e diventa valore consegnato.
Implicazioni Pratiche
Cosa fanno le aziende che vedo vincere davvero? Primo: trattano la discovery come lavoro a sé, time-boxed a 2-4 settimane, con deliverable chiari — ipotesi validate/invalidate, baseline riproducibile, metrica d’adozione definita.
L’approccio Agile con AI porta a miglioramenti nelle previsioni di sfide di progetto e consente ai team di adattarsi rapidamente alle nuove esigenze. Nella pratica, questo si traduce in: [forbes.com]
- Non vendere un progetto AI come fixed-price waterfall — vendi sprint con KPI misurabili e deliverable incrementali
- TDSP come backbone operativo — struttura Microsoft adattata al ritmo degli sprint
- Governance fin dal giorno 1 — responsible AI, data ownership e privacy non sono “fasi finali”
- MLOps nel contratto — budget per osservabilità, SLA/SLO, criteri di decommission
I dati di survey industriale (DACH region, 64 respondent) confermano sfide significative nell’esecuzione di progetti AI e un’opportunità sostanziale di miglioramento per chi adotta pattern incrementali. (SpryFox, 2025) [onecdn.io]
La domanda che il cliente fa — “quando sarà pronto?” — è spesso la domanda sbagliata. Quella giusta è: “qual è il primo valore misurabile che possiamo consegnare in 3 settimane?” Ed è lì che si gioca la differenza tra un progetto AI di successo e uno che finisce in un PowerPoint dimenticato.
Conclusioni
Riflettendo sui progetti che mi hanno insegnato di più, non ricordo un fallimento dovuto a “un algoritmo sbagliato” quanto a “apprendimento tardivo”. Waterfall fallisce nell’AI perché presuppone che la conoscenza sia trasferibile in blocco all’inizio. Le metodologie che funzionano — CRISP-DM, TDSP, MLOps, GenAI Lifecycle, Agile AI — funzionano perché ammettono l’ignoto, lo misurano e lo riducono iterando.
La mia posizione è semplice: scegliete un telaio di pratiche che incentivi feedback veloci, metriche esplicite e responsabilità chiare in produzione. Mettete MLOps, valutazione e governance nel contratto, non nell’appendice.
“Un buon processo non garantisce il successo, ma rende i fallimenti piccoli, istruttivi e recuperabili.”
La vera sfida non è tecnica, ma umana.
Riferimenti
- Arcidiacono, G. (2026, January). Comparative research on IT project failure rates: A 2025 longitudinal update. PM World Library.
- Bayram, F., & Ahmed, B. S. (2024). Towards Trustworthy Machine Learning in Production: An Overview of the Robustness in MLOps Approach. arXiv:2410.21346. Karlstad University.
- ScienceDirect. (2024). An analysis of the challenges in the adoption of MLOps. Journal of Innovation & Knowledge.
- ScienceDirect. (2025). Impact of artificial intelligence on project management. Journal of Innovation & Knowledge.
- Springer. (2025). Generative Artificial Intelligence in Agile Software Development. Lecture Notes in Computer Science.
- SpryFox. (2025, July). AI Project Success and Failure: Industry Survey Report (DACH region, 64 respondents).
Rispondi